Los que solemos instalar habitualmente distribuciones Linux para probar o simplemente por cambiar de entorno hay algo que debemos hacer periódicamente: limpiar las entradas que se han grabado en el boot del UEFI y que siguen ahí aunque la distribución que las incluyó ya no existe en el disco. No es que hagan mucho daño, pero si mantenemos limpito nuestro sistema de arranque, mejor que mejor.
Para ello tenemos que tener instalada la utilidad «efibootmgr», la cual está presente en todas las distribuciones principales de Linux, por lo que se podrá instalar directamente del sistema de paquetes que corresponda, por ejemplo en Fedora/Red Hat sería:
sudo dnf install efibootmgr
Una vez instalada, la ejecutamos abriendo un terminal y lanzando el comando:
efibootmgr
El cual nos dará un listado de las entradas que tenemos grabadas en este momento. Por ejemplo, en mi caso me listó lo siguiente:
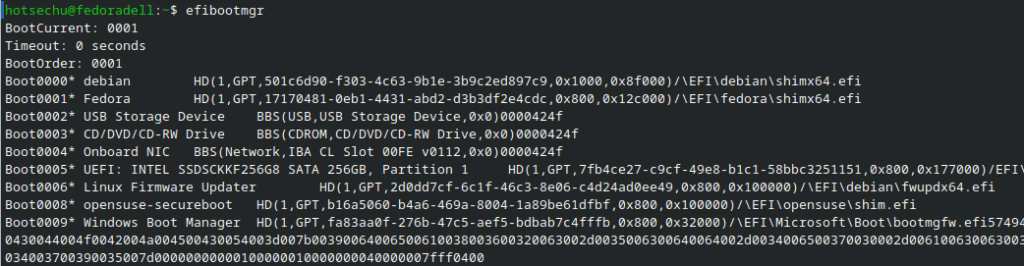
Terminal Linux en el que se observa la salida de pantalla del comando efibootmgr
Información interesante que aparece:
En la primera línea tenemos el BootCurrent, que nos dice cuál de las entadas listadas a continuación es la actualmente seleccionada para arrancar en primer lugar.
En segundo lugar aparece el Timeout, que es el tiempo en segundos que el boot espera antes de arrancar. En mi caso, como solo tengo un sistema operativo instalado, la tengo a 0 segundos.
En tercer lugar se muestra el BootOrder, que es el orden en el que se va a arrancar el sistema. En el ejemplo solo aparece el boot 0001 porque no hay más orden de arranque, solo tengo un sistema operativo instalado y disponible. Si tuviera más, me aparecería el número correspondiente a cada uno a continuación (0008, 0004….) en el orden en el que se hubieran seleccionado para arrancar.
Las entradas que aparecen con un «*» a continuación de su etiqueta es porque aún están activas, aunque no sea posible utilizarlas. Esto es así porque la desinstalación de un sistema operativo ni elimina lo que tiene el boot UEFI ni lo modifica. Es por eso por lo que conviene de vez en cuando revisar que no se nos van quedando cosas obsoletas en él.
Para eliminar una entrada, por ejemplo en mi caso las distribuciones Linux que usé pero que ya no existen, lanzamos como root el comando:
efibootmgr -b 0008 -B
El cual elimina la entrada etiquetada como Boot0008, que corresponde a un antiguo OpenSUSE que estuve probando. Para el resto de entradas que no queramos mantener, se haría exactamente igual.